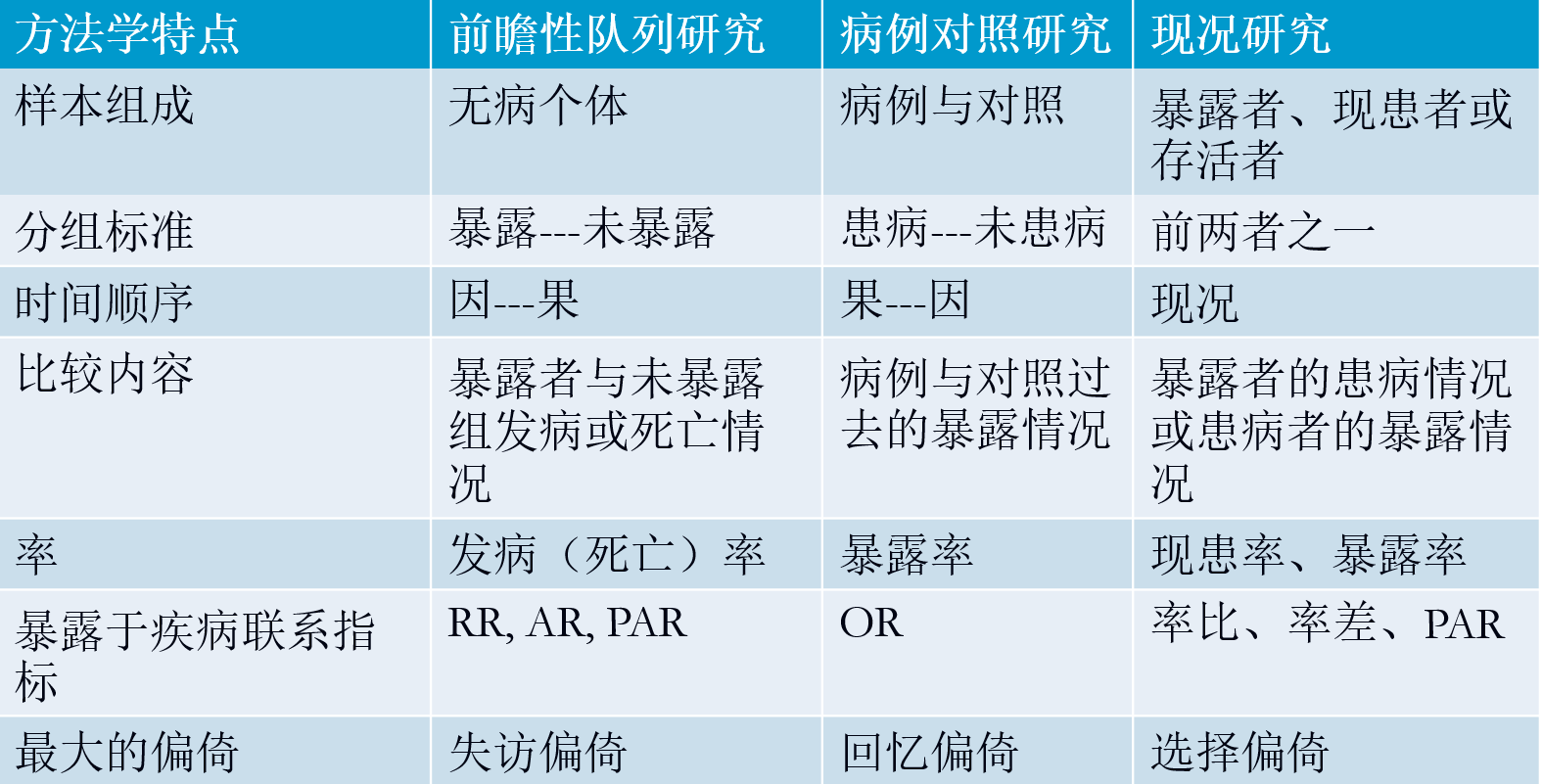
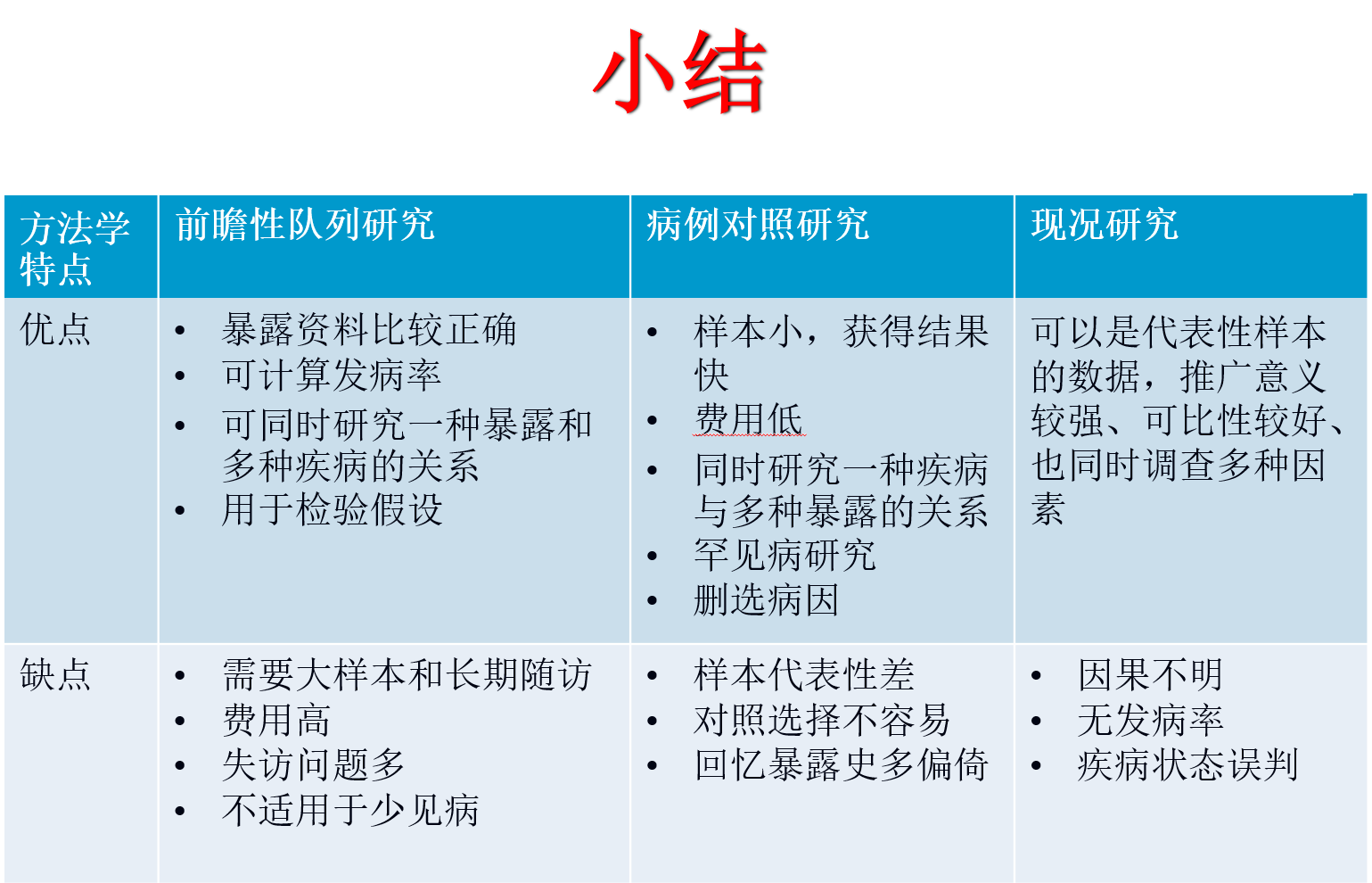
W3-队列研究

一、队列研究概述
• 也叫定群研究,是一种观察性研究方法
• 选定暴露和未暴露于某种因素的两个人群
• 追踪其各自的发病结局
• 比较两者发病结局的差异
• 判断暴露因素与发病有无因果关联及关联大小
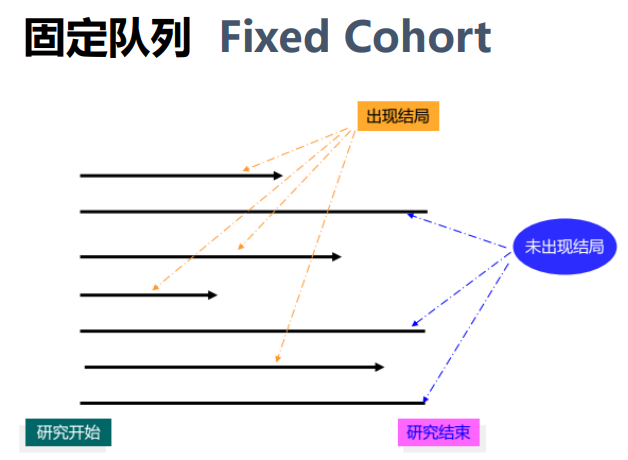
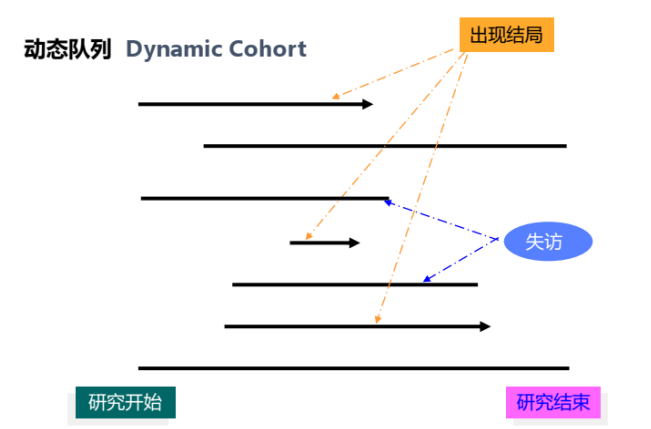
• 分为固定队列和动态队列(进入队列时间的区别)
1、暴露(exposure)
指接触过某种待研究的物质、具备某种特征或处于某种状态,暴露一定是根据研究目的来的,可以是有害的或有益的
2、危险因素(risk factor)
指能引起某特定不良结局(outcome),或使其发生的概率增加的因子,包括个人行为、 生活方式、环境和遗传等多方面的因素,危险因素的反面是保护因素
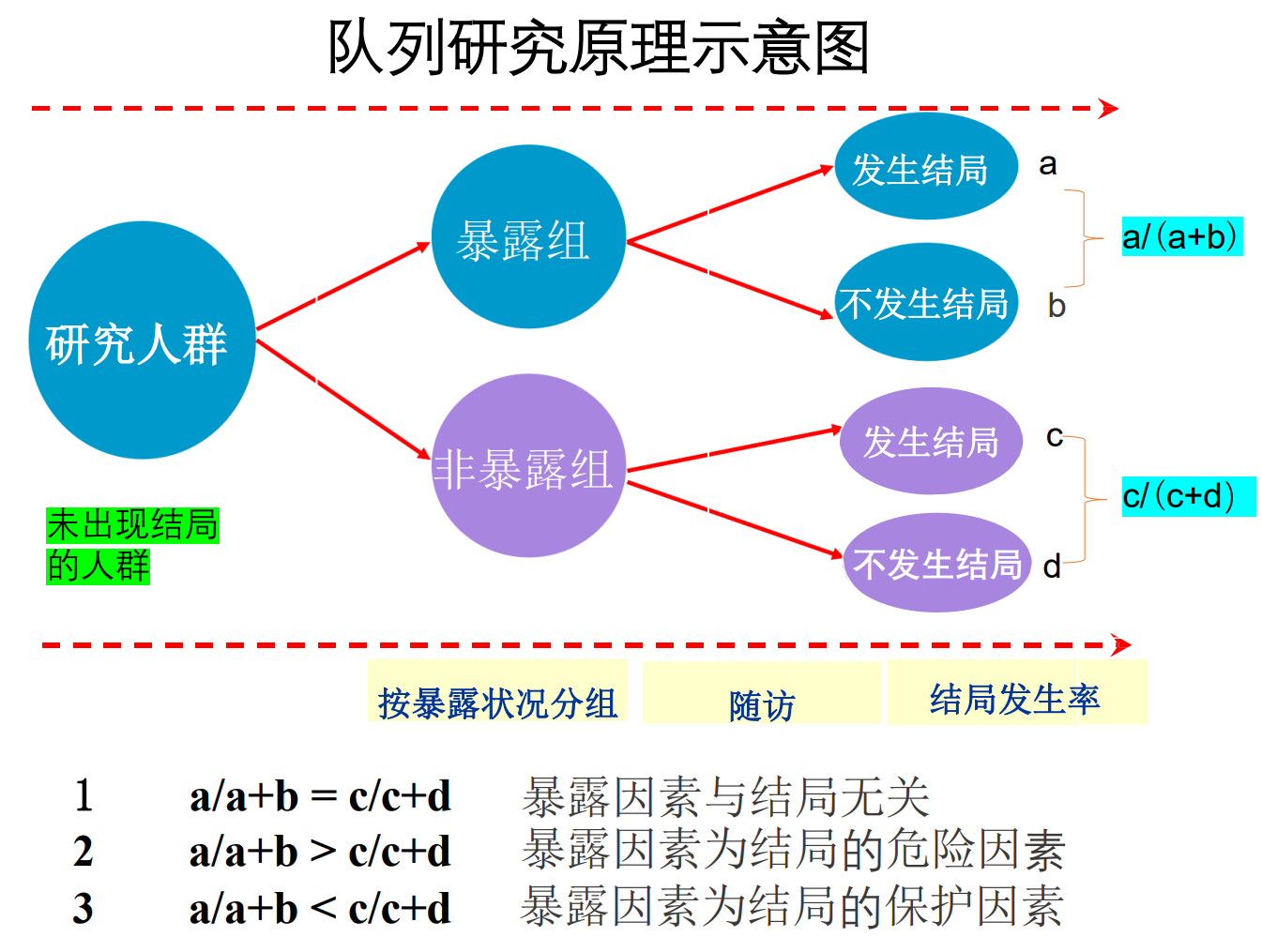
队列研究特点:
1、属于观察法
2、设立对照组
3、由“因”及“果”(exposure → outcome)
4、检验暴露与结局的因果联系能力较强
队列研究目的:
1、检验病因假设
2、评价预防措施效果
3、研究疾病的自然史
4、新药的上市后监测
分类
暴露测量时间与队列结束/研究结局出现时间的时间关系
过去→现在:历史性
过去→未来:双向性
现在→未来:前瞻性
(一)前瞻性队列研究
(prospective cohort study)
研究对象的分组是根据研究开始时(现时)研究对象的暴露状况而定的。此时,研究的结局还没有出现,还需要前瞻观察一段时间才能得到。
优点:资料的偏倚较小,结果可信
缺点:所需样本量大,观察世间长、花费大
选用原则:
1、应有明确的检验假设,检验的因素必须找准
2、所研究疾病的发病率或死亡率应较高,不低于千分之五
3、应明确规定暴露因素,并且应有把握获得观察人群的暴露资料
4、应明确规定结局变量,如发病或死亡,并且要有确定结局的简便而可靠的手段
5、应有把握获得足够的观察人群,并将其清楚地分成暴露组与非暴露组
6、大部分观察人群应能被长期随访下去,并取得完整可靠的资料
7、应有足够的人、财、物力支持该工作
(二)历史性队列研究
Historical/retrospective cohort study
研究对象的分组:过去某个时点暴露状况的历史材料
研究的结局:研究开始时已知,结局资料可从历史资料中获得
不需要前瞻性观察,性质依然是由因到果
优点:省时、省力、出结果快
缺点:因资料积累时未受到研究者的控制,所以,内容未必符合要求
应用原则:是否有足够数量的完整可靠的在过去某段时间内 有关研究对象的暴露和结局的记录
(三)双向性/混合型队列研究
在历史性队列研究之后,继续前瞻性观察一段时间,它是将前瞻性队列研究与历史性队列研究结合起来的一种设计模式
兼有两种队列的优点,相对地在一定程度上弥补了相互的不足
二、队列研究设计与实施
(一)研究因素/暴露的确定
主要暴露因素
在前期研究的基础上确定:如现况研究产生研究假设
暴露水平、累积暴露量、暴露时间、方式
暴露的测量:精确、简单、可靠
一个暴露对应多个结局
可能影响结局的因素
混杂因素、人口学特征
暴露因素的规定
必须有一个明确的规定
最好定量或分级指标
能测定暴露剂量则更好
暴露因素的分级
可用定量资料分级
不易获得准确的定量资料,故常用暴露水平分级
(二)结局(outcome)的确定
❖结局变量是观察人群中出现的预期的结果事件
❖可以是发病、死亡这样的终点事件
❖也可以是中间结局(分子或血清水平的变化)
❖可是正面(疾病康复)或负面的
❖可定性或定量
❖可以设多种结局,研究一因多果
结局定义需要非常明确!参考国内外的诊断标准来评估结局并严格遵守
(三)研究选择
研究现场选择的考虑因素
有足够符合条件的研究对象
领导重视、群众支持
医疗条件较好,交通较便利
发病率较高
有代表性
研究人群的选择
所有研究人群是易感人群
暴露人群选择:
职业人群(由于特殊职业原因暴露于某种危险因素的人群,如同济队列)
特殊暴露人群:日本的核辐射队列
一般人群(general population: China Health and Nutrition Survery)
有组织的人群团体 (学生,社团,退休人员,如NIH-AARP study)
对照人群的选择:
对照人群除未暴露于所研究的因素外,其它各种影响因素或人群特征(年龄、性别、民族、职业、文化程度等)都应尽可能地与暴露组相同,即具有可比性
常用对照形式(四种)
1、内对照(internal control)
选择一组研究人群A,将A中有E的作暴露组 ,A中无E的则为非暴露组(内对照)。
当E为定量变量时,所划分的最低档次暴露的人群为对照组。省事、可比性较好。
2、外对照(external control)
职业人群或特殊暴露人群需在其外去寻找对照组
对照组免受暴露组“污染” ,但需费力去组织另一个人群
3、总人口对照(total population control)
不设对照,是利用整个地区的现成的发病或死亡统计资料,即以全人口率为对照
优点:对比资料容易得到
缺点:资料较粗糙,可比性差,比较项目的精细程度低,对照中可能包含有暴露人群(所以适合暴露比例小的暴露因素)
4、多重对照
用上述两种或两种以上的形式的人群同时作对照,*以减少只用一种对照所带来的偏倚,增强结果的可靠性
关于对照注意:
在利用总人口对照时,应尽量选用与暴露组在时间、地区及人群构成上相近的总人群作对照,以减少偏倚
总人口对照的研究实际中不以粗率直接比较,应采用标化的方法,如计算标准化死亡率比
(四)确定样本量
(1)需考虑的几个问题
1、抽样方法:同现况研究
2、暴露组与非暴露组的比例:一般,非暴露组的样本量不宜少于暴露组的样本量。常用等量的样本量
3、失访率:常假设为10%,故按计算出来的样本量再加10%作实际样本。
(2)影响样本量(队列大小)的因素
1.对照组发病率的估计值P0
2.暴露组与对照组的发病率之差d=p1-p0
(d越大,样本量越小)
3.第一类错误概率α (假阳性)
(α越大,样本量越小)
4.第二类错误概率β(假阴性)
(β 越大,样本量越小;1- β =Power)
(感到困难?来看看6-统计推断)
(3)样本(队列大小)估计
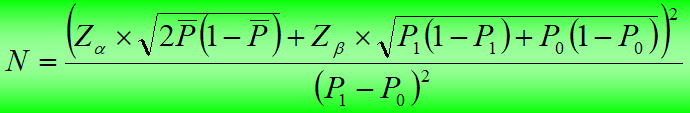
与病例对照研究的不同之处仅为符号P0与P1分别代表非暴露组与暴露组的发病率或死亡率。
P1:暴露组预期发病率
P0:对照组预期发病率
总结:这玩意用统计软件做,不用学
失访率
在估计样本量时,要预先估计失访率,防止在研究结束时因研究对象失访使样本量不足而影响结果分析。
通过按最大失访率为10% 进行估计,即将计算所得的样本量再加10%作为实际需要的样本量。
(五)资料收集与随访
(1)基线资料的收集
基线资料(baseline information):又称基线信息,指每个研究对象在研究开始时的基本情况,包括暴露的资料及个体的其他信息
基线资料具体包括:
1)暴露因素的暴露状况
2)疾病与健康状况
3)基本信息:年龄、性别、婚姻、职业、文化水平等个人情况
4)生活习惯、家庭工作环境及家族史
收集方法:
1.查阅医院、工厂、单位及个人健康保险的记录或档案
2.访问研究对象或其它能够提供信息的人;
3.对研究对象进行体格检查和实验室检查;
4.环境调查与检测
(2)随访(follow up)
随访对象:
暴露组观察研究对象
对照组观察研究对象
随访方法:
面对面访问、电话访问、自填问卷、定期体间、环境与疾病的监测、医院医疗与工作单位的出勤记录的收集等
注意事项:
1、对暴露组和对照组采用相同方法同等随访,追踪至观察终止
2、对失访者补访
3、失访原因分析
4、比较失访者与继续观察者基线资料,估计有无偏差
随访内容:
同基线资料
重点是结局变量
观察终点(研究对象出现预期结果):
出现预期结果,此人随访停止
未出现预期结果,继续随访至研究截止日期
未到截止日期,也未出现预期结果,但是中途脱离随访(失访)
观察终止时间(随访截止日期):
随访时间以基本潜伏期为依据
短,未能出现预期结果
长,失访率高并且耗费人力物力
随访间隔:
慢性病的随访间隔期一般为1-2年,但需考虑多种因素,如人力物力财力和当地的资源配置
调查者:
提前培训、保证客观一致性
质量控制:
严谨、诚实可靠、培训统一标准、调查员手册:SOP
常规监督措施:
1.由另一名调查员作抽样重复调查
2.人工或用计算机及时进行数值检查或逻辑检错
3.定期观察每个调查员的工作
4.对不同调查员所收集的变量分布进行比较
5.对变量的时间趁势进行分析
6.在访谈时使用录音机录音等
三、队列研究数据分析
随访结束后,核查、查错、数据录入、建库、数据整理、然后进行数据分析:
1)描述性统计:
研究对象的组成、人口学特征、随访时间及失访情况等;分析两组的可比性及资料的可靠性;(人群特征)
2)推断性分析:
分析两组率的差异,推断暴露的效应及其大小

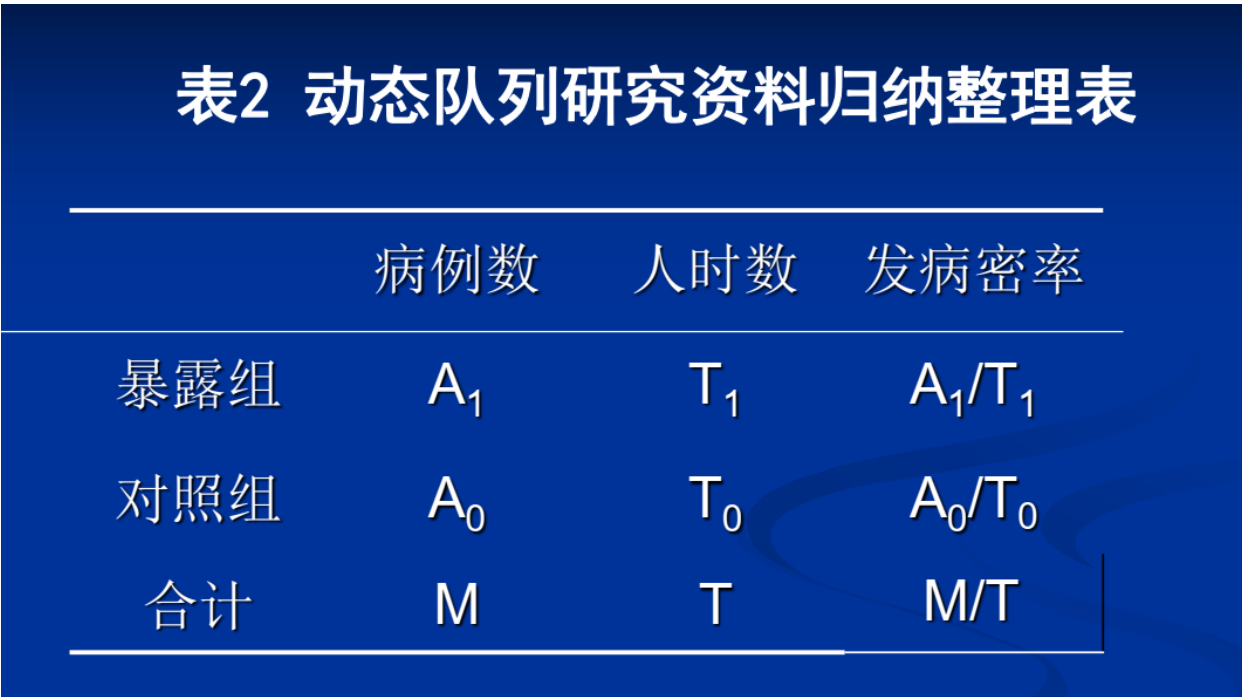
3)率的计算
1、累计发病率(cumulative incidence)

变化范围 0~1
适用条件: 样本大 人口稳定 整齐的资料(固定队列)
反应的是发病风险,报告时必须注明时间长短
2、发病密度 (incidence density)

暴露人口由于迁移、死于其它疾病、中途加入队列等,应将变动的人群转变为人时数代替人数来计算,如人年,此种发病率称发病密度。如1个观察对象观察满一年为1人年。
变化范围 0~∞
适用条件 观察时间长、人口不稳定、存在失访
人时(person time)
是将观察人数和观察时间结合作为分母的单位,人时是有单位的,如人年,人月等。
观察人时数=观察人数* 观察时间
一定的人时(人年)数可来自不同的人数与不同的观察时间,例如100人年可来自100人观察一年,或50人观察2年,或200人观察0.5年
常用单位:人年
常用的人年计算方法:
1.精确法:个人为单位计算人年,逐日相加(最常用)
每一成员的观察年数是从观察开始算起到终点事件出现或研究结束时经过的年数
人年=每人的随访年数相加
2.用近似法计算暴露人年:年头和年尾人数之和除以2
•样本量很大,不需要精确人年计算,不知道具体每人进出队列时间
•用平均人数乘以观察年数得到总人年数
•平均人数一般取相邻两年的年初人口的平均数或年中人口数。
•该法计算简单,但精确性较差。
3.用寿命表法计算人年:当年内进入或退出队列的个人均作1/2人年计算
3、标化死亡比(standardized mortality ratio ,SMR)
当研究对象数目较少,结局事件的发生率较低时,无论观察时间长短,都不宜直接计算率,而以全人口发病(死亡)率作为标准,算出该观察人群的理论发病(死亡)数
观察人群实际发病(死亡)数与理论发病(死亡)数之比,即为标化发病(死亡)比
最常用的是标化死亡比

SMR的意义
被研究人群发生(死于)某病的危险性是标准人群的多少倍
SMR=1
研究人群某病发病(死亡)危险=标准人群
SMR>1
研究人群某病发病(死亡)危险>标准人群,是标准人群的SMR倍
SMR<1
研究人群某病发病(死亡)危险<标准人群
显著性检验



建议去看9-卡方检验
三、效应的计算
1)相对危险度(relative risk, RR)
也叫危险度比(risk ratio)或率比(rate ratio),是暴露组发病(死亡)率与对照组发病(死亡)率的比值,简称RR。
RR=Ie/I0
RR说明暴露组发病或死亡为对照组的倍数。
RR>1说明暴露因素与疾病为正联系,暴露可能是危险因素;
RR<1说明暴露因素与疾病为负联系,暴露可能具有保护意义。
RR越大表明暴露的效应越大,关联越强
2) 归因危险度(attributive risk)AR
也称特异危险度、危险度差(risk difference, RD)和超额危险度,是暴露组与对照组发病率的差值。
AR表示:危险特异地归因于暴露因素的程度
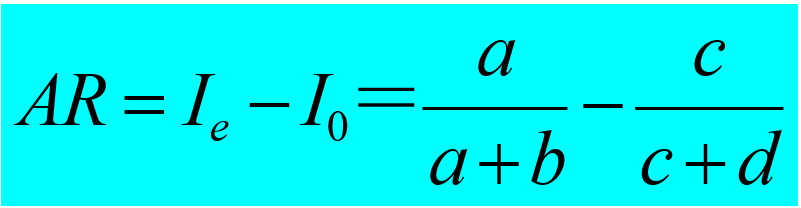
RR与AR的区别
RR评价暴露与疾病的联系强度,不说明绝对危险度的大小,用于病因研究
AR表示某因素对疾病的绝对危险,用于公共卫生决策
RR具有病因学的意义,AR更具有疾病预防和公共卫生上的意义
3)归因危险度百分比(AR%)
指暴露人群中发病归因于暴露的成分占全部病因的百分比。
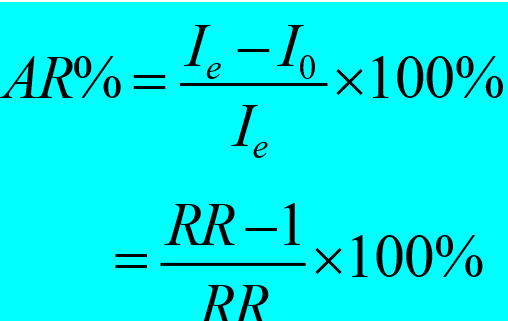
4)人群归因危险度 (population attributive risk,PAR)
PAR=It-I0
It为全人群的发病率或死亡率,I0为非暴露组的发病率或死亡率。
说明总人群中疾病的发生或死亡有可能归因于该暴露因素的部分。
5)人群归因危险度百分比(PAR%)
•指全人群中发病归因于暴露的成分占全部病因的百分比。
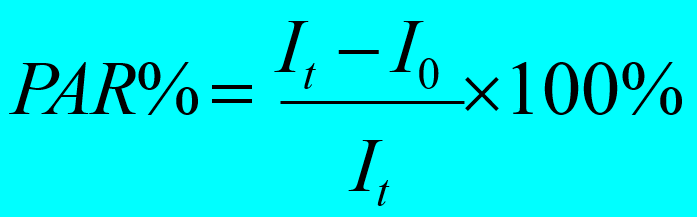
比较
RR和AR都说明暴露的生物学效应(暴露的致病作用有多大);
PAR和PAR%则说明暴露对全人群的危害程度,以及消除这个因素后可能使发病率或死亡率减少的程度,它既与RR和AR有关,又与人群中暴露者的比例有关
常见偏倚及其控制方法
1.选择偏倚 (selection bias)
研究人群在一些重要因素方面与一般人群或待研究的总体人群存在差异,而导致研究结果的偏倚。
失访偏倚 (loss to follow-up bias)
研究对象因迁移、外出、死于非终点疾病或拒绝继续参加观察而退出队列所引起的偏倚。本质上属于选择性偏倚。如暴露组和非暴露组失访人数相等,失访和未失访者的发病率相等则认为对结果影响不大
自我选择偏倚(self-selection bias)
不响应偏倚(non-response bias)
健康工人偏倚 (healthy worker bias)
产生原因
选择对象的方法不当
最初选定参加研究的对象中有人拒绝参加或失访
历史性队列研究中部分档案丢失或记录不全
志愿者队列, 往往健康而缺乏代表性,或有某种特殊习惯
研究开始时未能发现早期病人等
选择偏倚控制(重在预防)
1.预防选择偏倚首先要用正确抽样方法,即严格遵守随机化的原则;严格按规定的标准选择对象;不轻易放弃随访;新加入或退出者的基本情况与正常选择参加的人群进行应一致。
2.防止失访偏倚主要靠尽可能提高研究对象的依从性和应答率,失访率达应低于15-20%。
3.历史性队列研究要求目标人群档案资料比较齐全,如果不全也要控制在一定范围内
评估措施:查询失访者是否死亡及死亡原因、比较失访者和未失访者基线资料、再次联系、敏感性分析等
2.信息偏倚(information bias)
在获取暴露、结局或其他信息时所出现的系统误差。常见:
缺失信息 (missing data)
回忆偏倚(recall bias)
观察者偏倚(observer bias)
采访者偏倚 (interviewer bias)
产生原因
•疾病、暴露标准不明确
•检验仪器不精确、检验技术不熟
•询问技巧不佳、记录错误,造假等
控制信息偏倚(重在预防)
1.客观层面:选择精确稳定的测量方法、调准仪器、严格操作规程、提高诊断技术、明确标准等。
2.调查员培训、统一标准、提高责任心和诚信度。
3.从预调查中学习。
评估措施:小样本二次随机调查、敏感性分析等
3.混杂偏倚(confounding bias)
第三变量作用下歪曲暴露因素与结局,第三个变量叫做混杂变量(既与疾病相关也与暴露相关)
如何控制
设计阶段采用限制和配比的方法以及提前收集相关混杂因素信息,分析阶段采用标准化方法计算发病率(死亡率),按混杂因素(年龄、性别)进行分层及多因素分析等
五、队列研究的优点及缺点
(一)队列研究优点
- 暴露资料收集在结局之前,严格设计,资料完整可靠、信息偏倚较小
- 可以分析暴露的病因作用和公共卫生意义
- 由“因”至“果”观察,检验病因假说能力较强
- 能了解疾病的自然史,一次调查可观察多种结局
(二)队列研究的缺点
1、不适用于研究人群中发病率很低的疾病
2、观察时间长而难以避免失访,不易收集完整可靠的资料
3、 随访过程中,未知变量引入人群,或人群已知变量变化, 可影响结局,使分析复杂化
4、耗费人力、物力、财力、时间多,组织和后勤工作艰巨
5、最初始队列研究一个暴露因素为主
更优的解决方案:综合队列研究、大数据队列研究